
直播开发入门教程·直播基础
前言
移动互联网时代,直播是一种重要的媒体承载以及信息传播的媒介方式,在早几年经历了蓬勃发展,这里引用一段游戏直播的发展简史。
**2005 年- 2013 年是游戏直播的青铜时代,**游戏直播还处于萌芽状态,以9158、YY为代表的秀场直播一统天下。
**2014 年- 2016 年是游戏直播的白银时代,**手游产业的爆发以及4G网络的普及 ,为游戏直播提供了成长土壤,斗鱼、虎牙、战旗、龙珠、熊猫等知名直播平台诞生 ,秀场直播、素人直播也仍在快速发展之中,“百播大战”爆发,一系列直播乱象引来国家监管,直播行业第一轮洗牌开始。
**2017 年至今是游戏直播的黄金时代,**百播大战尘埃落定,游戏直播行业确立了“两超多强”格局,虎牙率先赴美上市,腾讯同时投资斗鱼和虎牙、加速行业洗牌,全民直播、熊猫直播先后退出市场,但西瓜视频、快手等后起之秀仍有意布局游戏直播。

经过“百播大战”之后,直播巨头的地位基本奠定。各行各业也发展出来各式各样的直播形式,如视频答题、云监控、直播带货、云游戏,直播技术在这一过程中也在稳健发展,更智能的CDN分发、QUIC和WebRTC的应用、编解码和传输协议的优化升级给直播带来了更流畅的体验和更多的可能性。
本系列文章旨在编写一个更系统、简单的直播开发入门教程,计划分为三个部分讲解
- 直播基础知识(本篇)
- 如何搭建一个能运行的直播平台
- 直播server的后台开发
本篇将循序渐进的介绍采集、编码、推流、转码等直播流程,对整个直播体系有个基本认知,有谬误或者不清晰的地方欢迎评论留言。
以下是一个基本的直播推流和拉流的过程。
以在斗鱼直播开播为例,斗鱼开播工具负责前面部分,斗鱼客户端负责后面部分。

直播基础:采集
音视频的采集和编码是直播流程里最开始的一环,依赖设备的能力采集音频和视频数据,一般都使用AAC+H264组合。
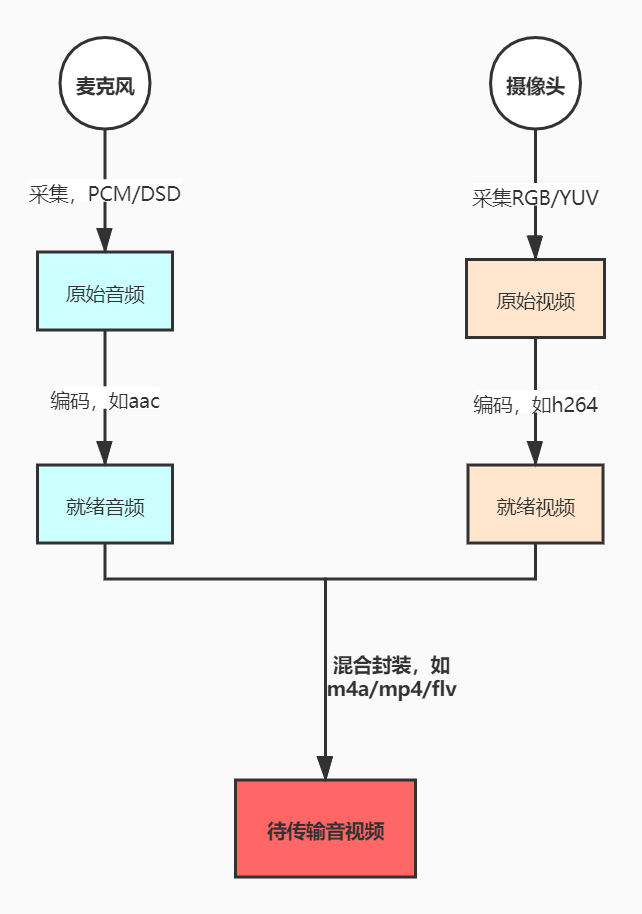
音频采集
音频的采集过程主要通过设备将环境中的模拟信号采集成 PCM 编码的原始数据。
PCM是常用的音频编码,全称是Pulse Code Modulation(脉冲编码调制),从名字来看一头雾水

其实它主要是将模拟信号成数字信号,简单来说就是利用一个固定的频率对模拟信号进行采样,从而生成一段连续的脉冲,把这些脉冲的幅值按一定的精度进行量化。
 听起来是不是懂了?
听起来是不是懂了?
PCM数据是最原始的音频数据,因为完全无损所以音质非常好,常用文件扩展名是.pcm和.raw,通常它们是不能直接播放的,需要经过重新编码、封装后才可正常播放,常见的编码方式我们比较熟悉,包括无损压缩(ALAC、APE、FLAC)和有损压缩(MP3、AAC、OGG、WMA)两种。
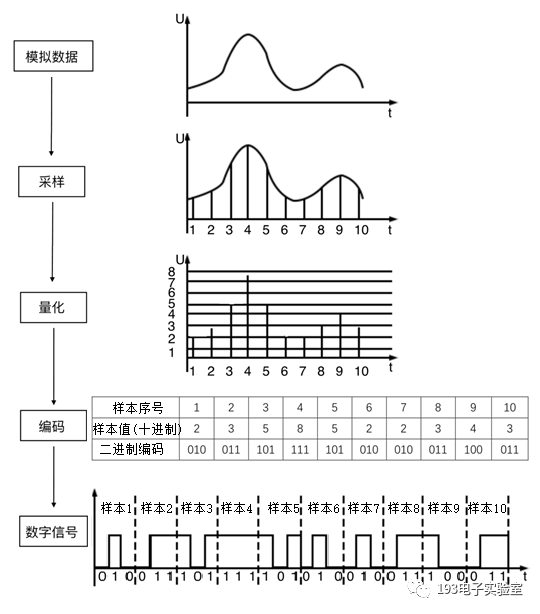
如下图所示,最后生成数字信号供我们使用和传输。
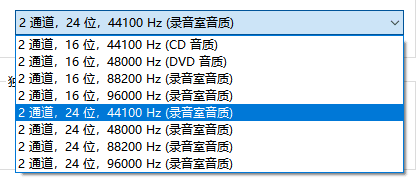
工作中常用的是一些采集参数、编码参数的调整,比如ffmpeg里使用ac调整声道数、使用ar设置采样率:
ffmpeg -i /home/test/jeff&arvon.mp3 -ac 1 -ar 48000 -y test.mp3
这里介绍一下常用的音频参数
-
采样率 Sample Rate
采样率(采样频率)即每秒内进行采样的次数。符号是fs,单位是Hz。采样率越高,数字波形的形状就越接近原始模拟波形,声音的还原就越真实。
-
采样位数 Bit Depth
采样位数(又称位宽,位深,位深度),字面意义就是采样值的二进制编码的位数,其实就是用多少个点来描述声音信号的强度。采样位数反应了采样系统对声音的辨析度,位数越高,对声音的记录就越精细,所以也称之为**采样精度,采样深度。16bit 表示每一个采样点采集2个byte的数据,也就是2个字节。
-
声道 Sound Channel
声道是指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号,通俗的说声道数就是录音时的麦克风数量,也是播放时的音响数量。声道数,也叫通道数,轨道数,音轨数。
常见的声道数有单声道(Mono),双声道(即立体声,Stereo),5.1声道,7.1声道等。这里的 .1声道指的是低音声道。
-
比特率 Bit Rate
指经过编码后的音频数据每秒钟需要用多少个比特来表示,比特率是每秒播放连续的音频或视频的比特的数量,是音视频文件的一个属性,也俗称为"码率"。
我们做个实战,假设一个音频文件的码率是128kbps,实际指的是128kb/s,那1分钟的音频大小在0.92M左右
128*1000=128000b/s÷8=16000B/s÷1024=15.625KB/s
15.625KB/s*60=937.5KB/分钟÷1024=0.9155MB/分钟
图片采集
图像采集的图片可以组合成一组连续播放的动画,即构成视频中可肉眼观看的内容,其实这里说的也是视频采集。
图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据,然后经过编码压缩成 H.264 等格式的数据分发出去。
常见的视频封装格式我们也很熟悉,包括有:MP4、AVI、MKV、WMV、RMVB 等。
在图像采集阶段,涉及的主要技术参数包括:图像传输格式、图像格式、传输通道、分辨率以及采样率。
- 图像传输格式:通用影像传输格式(Common Intermediate Format)是视讯会议(video conference)中常使用的影像传输格式。
- 图像格式:通常采用 YUV 格式存储原始数据信息,其中包含用 8 位表示的黑白图像灰度值,以及可由 RGB 三种色彩组合成的彩色图像。
- 传输通道:正常情况下视频的拍摄只需 1 路通道,随着 VR 和 AR 技术的日渐成熟,为了拍摄一个完整的 360° 视频,可能需要通过不同角度拍摄,然后经过多通道传输后合成。
- 分辨率:随着设备屏幕尺寸的日益增多,视频采集过程中原始视频分辨率起着越来越重要的作用,后续处理环节中使用的所有视频分辨率的定义都以原始视频分辨率为基础。视频采集卡能支持的最大点阵反映了其分辨率的性能。
- 采样频率:采样频率反映了采集卡处理图像的速度和能力。在进行高度图像采集时,需要注意采集卡的采样频率是否满足要求。采样率越高,图像质量越高,同时保存这些图像信息的数据量也越大。
类比于音频的PCM,这里介绍RGB和YUV颜色模式。
RGB
图像的采集可以通过摄像头或者截取屏幕来获取的图像数据,在图像储存中,通过记录每个像素的红绿蓝强度,来记录图像的方法,称为RGB模型。
一张 1280 * 720 大小的图片,就占用 1280 * 720 * 3 / 1024 / 1024 = 2.63 MB 存储空间。
YUV
实际上,我们的眼睛对于亮度相比于颜色更敏感,因此可以针对于此使用另一种颜色模型。
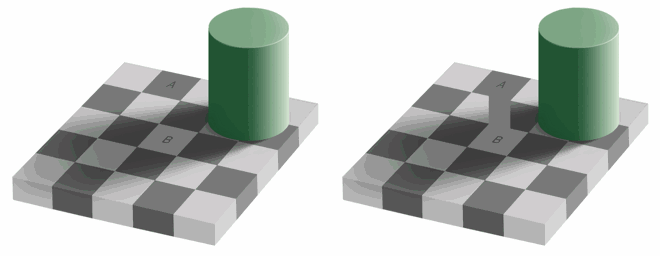
如上图所示,区域 A 与区域 B其实是相同的颜色,第一张很难区分出来,这跟我们人眼的构造相关,人眼更加注意光线明亮度。所以针对这一特点存在另一种颜色模型 YUV 。
人眼对色度的敏感程度低于对亮度的敏感程度。主要原因是视网膜杆细胞多于视网膜锥细胞,其中视网膜杆细胞的作用就是识别亮度,视网膜锥细胞的作用就是识别色度。所以,眼睛对于亮度的分辨要比对颜色的分辨精细一些。
YUV是电视系统所采用的一种颜色编码方法,它可以通过数学转换,将RGB三通道转换为一个代表亮度的通道(Y,又称为Luma),和两个代表色度的通道(UV,并称为Chroma)来记录图像的模型。
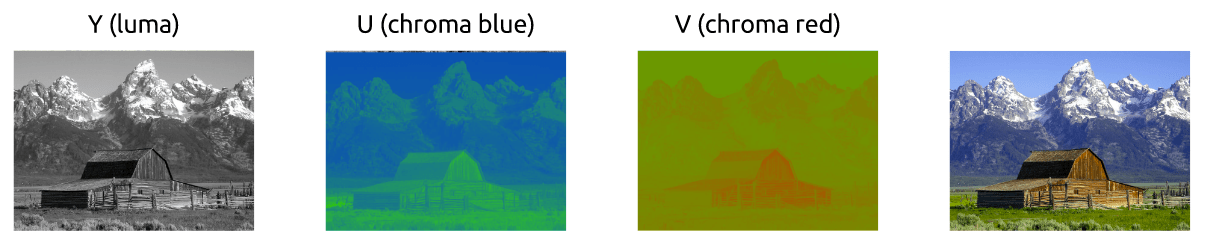
YUV 图像的主流采样方式有如下三种,主要区别是,亮度信息全传输,UV色度进行采样传输,这里就不进行展开了:

- YUV 4:4:4 采样:YUV三个信道的抽样率相同,水平采样
- YUV 4:2:2 采样:每个色差信道的抽样率是亮度信道的一半,水平采样
- YUV 4:2:0 采样:水平和垂直采样。它指得是对每行扫描线来说,只有一种色度分量以2:1的抽样率存储。相邻的扫描行存储不同的色度分量, 也就是说,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0
YUV与RGB视频信号相比,最大的优点在于占用更少的带宽,极端情况下(4:2:0 ),YUV只需要占用RGB一半的带宽。同时由于Y 和 UV 分量是分离的,还能够兼容黑白显示设备、减少色差信号干扰带来的影响(恒定亮度原理,亮度不影响)。
在采集完毕后,一般还会进入美颜阶段,实现动态贴纸,美颜滤镜,视频美化等效果,这里面有个坑,之前我们团队自研SDK,刚开始的时候直播出现音画分离的情况大多数都是因为视频处理后时间戳未同步导致的。
直播基础:编解码和封装
为什么需要视频编码
当需要存储视频或者网络传输时,无论是使用 RGB 还是 YUV 格式,所需要的码率和存储空间都是非常大的。原始视频数据存储空间大,一个 1080P 的 7 s 视频需要 817 MB,而经过 H.264 编码压缩之后,视频大小只有 700+ k ,这样才可以满足实时传输的需求。
目前常见的编码格式有MPEG-1、MPEG-2、MPEG-4、H.263、H.264,由于H.264具有更强的压缩效果与更好的兼容性,是目前主流的编码协议。
随着压缩技术持续发展,H.265协议逐渐进入应用阶段,H.266标准进入制定阶段,理论上来说,同等1080P画质下,H.265会比H.264要节省带宽30%~40%,分辨率越高,H265的压缩收益越明显。目前直播领域传输普遍采用的RTMP协议还不支持H.265,但是可以通过自行扩展RTMP来达到支持的目的。

编码的原理
编码的本质是为了去除图像的冗余信息,达到缩减体积的目的,一般以下几种冗余类型
-
空间冗余:图像相邻像素之间有较强的相关性
同一张图像中,有很多像素点表示的信息是完全一样的,如果对每一个像素进行单独的存储,必然会非常浪费空间

-
时间冗余:视频序列的相邻图像之间内容相似
时间冗余是指多张图像之间,有非常多的相关性,由于一些小运动造成了细小差别。如果对每张图像进行单独的像素存储,在下一张图片中又出现了相同的,也会非常浪费空间
-
编码冗余:不同像素值出现的概率不同
类似于哈夫曼编码,一幅图像中不同像素出现的概率是不同的。对出现次数比较多的像素,用少的位数来编码。对出现次数比较少的像素,用多的位数来编码,能够减少编码的大小。
-
视觉冗余:人的视觉系统对某些细节不敏感
利用人的视觉系统对某些细节不敏感。压缩视觉冗余度就是去掉那些相对人眼而言是看不到的或可有可无的图象数据
-
知识冗余:规律性的结构可由先验知识和背景知识得到
有许多图像的理解与某些基础知识有相当大的相关性。例如,人脸的图像有固定的结构,嘴的上方有鼻子,鼻子的上方有眼睛,鼻子位于正面图像的中线上等等。这类规律性的结构可由先验知识和背景知识得到,我们称此类冗余为知识冗余。根据已有知识,对某些图像中所包含的物体,可以构造其基本模型,并创建对应各种特征的图像库,进而图像的存储只需要保存一些特征参数,从而可以大大减少数据量。
-
结构冗余:某些图片中存在固定的分布模式
在某些场景中,存在着明显的图像分布模式,这种分布模式称为结构。图像中重复出现或相近的纹理结构,结构可以通过特定的算法来生成。例如:方格状的地板,蜂窝,砖墙,草席等等图像结构上存在冗余。已知分布模式,就可以用算法生存图像。
H.264编码基础概念介绍
由于我们目前最常用的视频编码还是h.264,直播开发基本绕不开它

这里讲一下它的协议基础概念。
在H.264协议里定义了三种帧,完整编码的帧叫 I 帧,参考之前的 I 帧生成的只包含差异部分编码的帧叫 P 帧,还有一种参考前后的帧编码的帧叫 B 帧。

**I 帧(Intra-coded picture):**即帧内编码图像帧,I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)。又称为内部画面 (intra picture),I 帧通常是每个 GOP(MPEG 所使用的一种视频压缩技术)的第一个帧,经过适度地压缩,做为随机访问的参考点。有如下特点:
- 它是一个全帧压缩编码帧。它将全帧图像信息进行 JPEG 压缩编码及传输;
- 解码时仅用 I 帧的数据就可重构完整图像;
- I 帧描述了图像背景和运动主体的详情;
- I 帧不需要参考其他画面而生成;
- I 帧是 P 帧和 B 帧的参考帧,其质量直接影响到同组中以后各帧的质量;
- I 帧是帧组 GOP 的基础帧(第一帧),在一组中只有一个 I 帧;
- I 帧不需要考虑运动矢量;
- I 帧所占数据的信息量比较大。
**P帧(Predictive-coded Picture):**即前向预测编码图像帧。P 帧表示的是这一帧跟之前的一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。
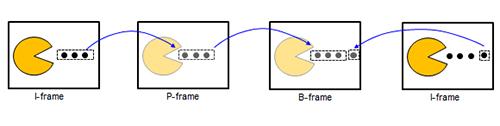
B帧(Bidirectionally predicted picture): 即双向预测编码图像帧。B 帧是双向差别帧,也就是 B 帧记录的是本帧与前后帧的差别,换言之, B 帧以前面的 I 或 P 帧 和后面的 P 帧为参考帧,要解码 B 帧不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。由于直播场景的特殊性,一般不使用B帧。
一般平均来说,I的压缩率是7(跟JPG差不多),P是20,B可以达到50,可见使用B帧能节省大量空间,节省出来的空间可以用来保存多一些I帧,这样在相同码率下,可以提供更好的画质。
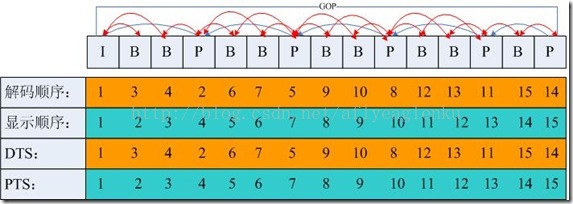
**帧分组(GOP,Group of picture):**就是一个I帧到下一个I帧这一组的数据,包括B帧/P帧。
如果GOP分组中的P帧丢失就会造成解码端的图像发生错误,为了避免花屏问题的发生,一般如果发现P帧或者I帧丢失就不显示本GOP内的所有帧.只到下一个I帧来后重新刷新图像。当这时因为没有刷新屏幕,丢包的这一组帧全部扔掉了,图像就会卡在哪里不动,就是卡顿的原因。
还有两个时间戳分别是:
DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。
PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
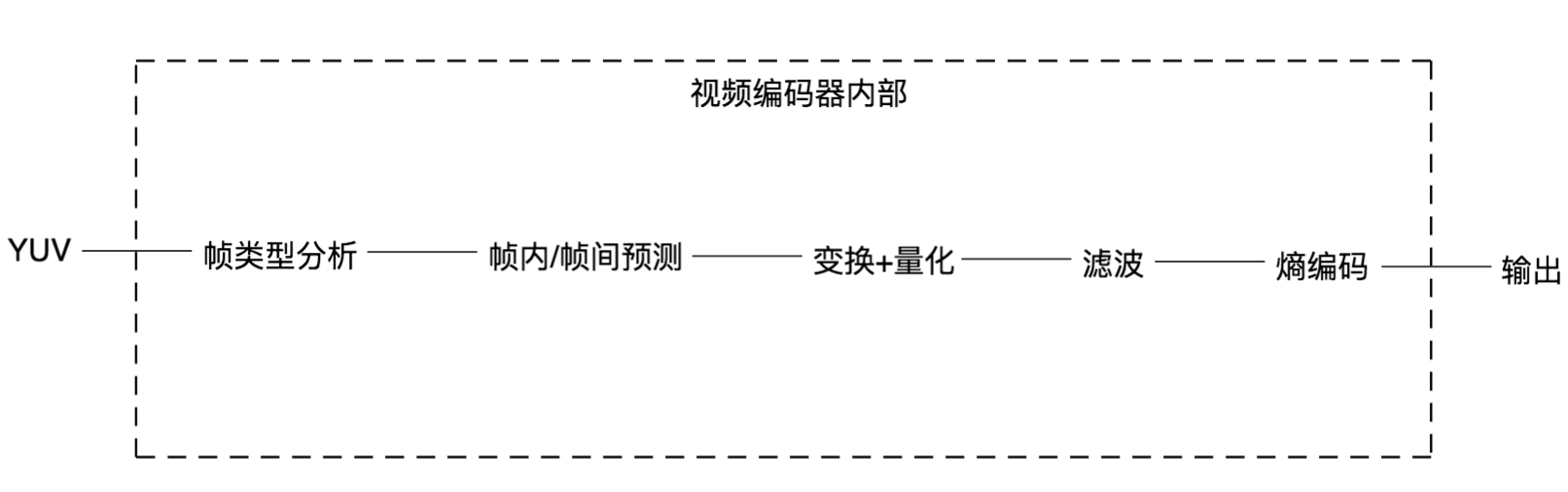
视频编码步骤
一般编解码器由 编码器和解码器组成,在后续的系列文章我们会分析下对应的代码和结构,以下是一个比较完整的编码流程(预测->变换->量化->熵编码):
最后,再进行视频封装,封装格式是按照一定的格式规则把编码后的视频和音频按照放在一起,最重要的作用就是让音视频同步。目前主流的直播封装是FLV/TS。
这时候可能疑问,我们可以使用AVI或者MP4作为封装格式用于直播吗
答案是不可以,因为avi和mp4都不是流媒体格式。 mp4 本身数据结构是 box 嵌套 box,播放时依赖于外层 box 的 meta 信息,所以普通的 mp4 视频只能把整个索引文件下载下来然后用户才能播放,直播场景不能预先生成meta文件所以不可行。
但是有一个MP4的衍生格式fmp4(Fragmented mp4)是能够支持的,整体设计类似于FLV。
直播基础:推流和拉流
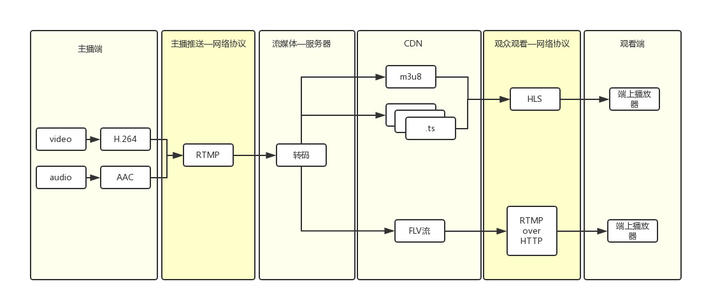
经过视频采集并编码、封装完成后,进入推流环节,通过流媒体协议发送到流媒体服务器。
目前互联网直播主流的推流协议使用RTMP(over TCP),拉流方案有HTTP-FLV/HLS/RTMP;而摄像头的实时视频流普遍采用的是 RTSP (over UDP),最大的优势就是低延迟。
RTMP
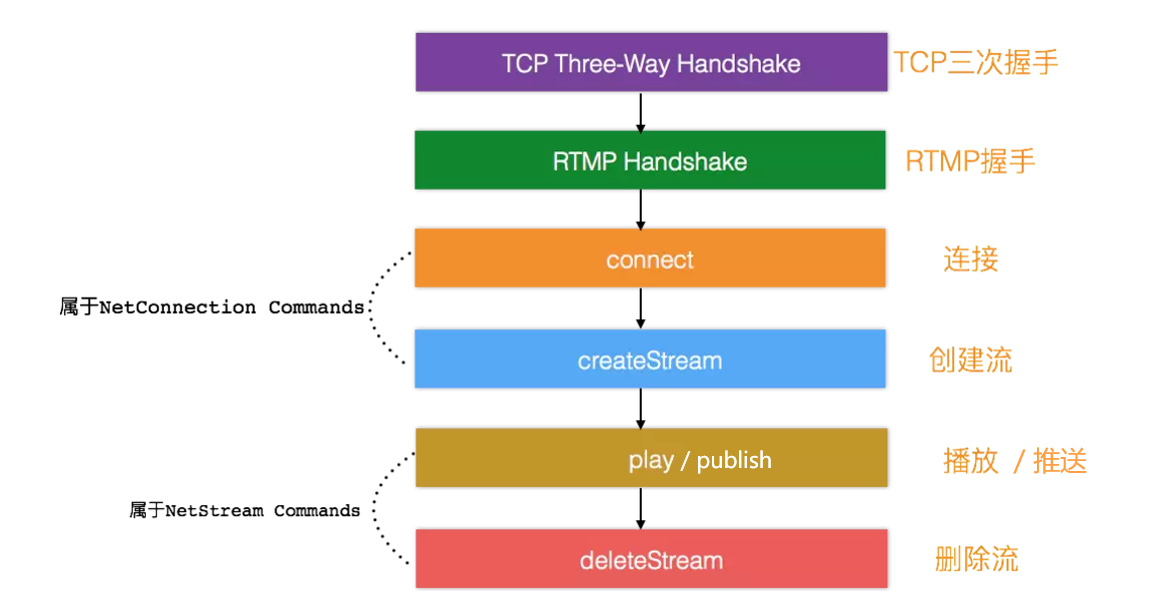
全称Real Time Messaging Protocol,是Adobe的专利协议,既可以用来推流也可以用于拉流,但目前主要用于直播推流端,在播放端的使用非常少。相对其他协议而言,RTMP协议初次建立连接的时候握手过程过于复杂,视不同的网络状况会带来给首开带来100ms以上的延迟,基于RTMP的直播一般内容延迟在2~5秒。
HTTP-FLV
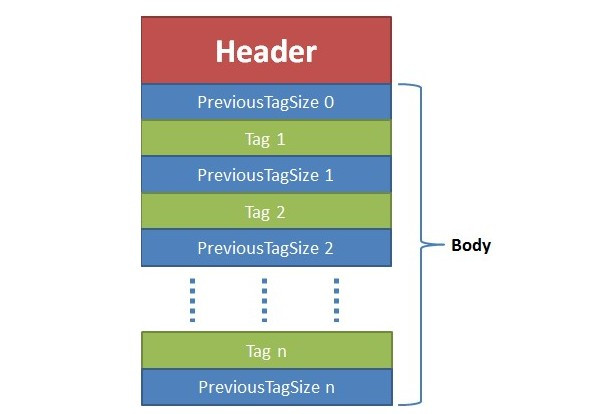
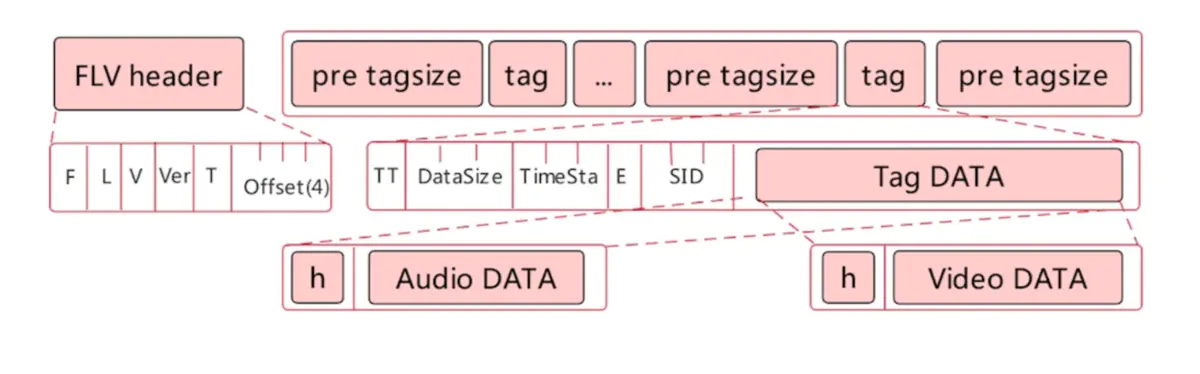
FLV (Flash Video) 是 Adobe 公司推出的另一种视频格式,是一种在网络上传输的流媒体数据存储容器格式。其格式相对简单轻量,不需要很大的媒体头部信息。整个 FLV 由 The FLV Header, The FLV Body 以及其它 Tag 组成,因此加载速度极快。
HTTP-FLV则是将流媒体数据封装成 FLV 格式,然后通过 HTTP 协议传输给客户端。相对于RTMP,HTTP更简单和广为人知,而且不担心被Adobe的专利绑架。内容延迟同样可以做到2~5秒,打开速度更快,因为HTTP本身没有复杂的状态交互。所以从延迟角度来看,HTTP-FLV要优于RTMP,并且现在也有开源库比如flv.js支持H5,其简要原理是在获取到FLV格式的音视频数据后通过原生的JS去解码FLV数据,再通过MSE API 喂给原生HTML5 Video标签(HTML5 原生仅支持播放 mp4/webm 格式,不支持 FLV)。
HLS(Http Live Streaming)
由苹果提出基于HTTP的流媒体传输协议,跨平台性比较好,HTML5可以直接打开播放,移动端兼容性良好,但是缺点是延迟比较高。
HLS 主要的两块内容是 .m3u8 文件和 .ts 播放文件。接受服务器会将接受到的视频流进行缓存,然后缓存到一定程度后,会将这些视频流进行编码格式化,同时会生成一份 .m3u8 文件和其它很多的 .ts 文件。
| RTMP | HTTP-FLV | HLS | |
|---|---|---|---|
| 传输方式 | TCP | 基于HTTP的RTMP | HTTP |
| 优点 | 延时低 | 延时低,支持H5 | 跨平台,支持H5 |
| 兼容性 | 适合推拉流 | 使用flv.js可在HTML播放 | 移动端和WEB支持良好 |
| 延时 | 1~3s | 1~3s | 超过10s |
| 适合场景 | 推流 | PC端 | PC端&移动端拉流 |
现阶段而言,直播的延时主要还是在网络分发上,一般场景通常还是采用兼容性最好的HLS
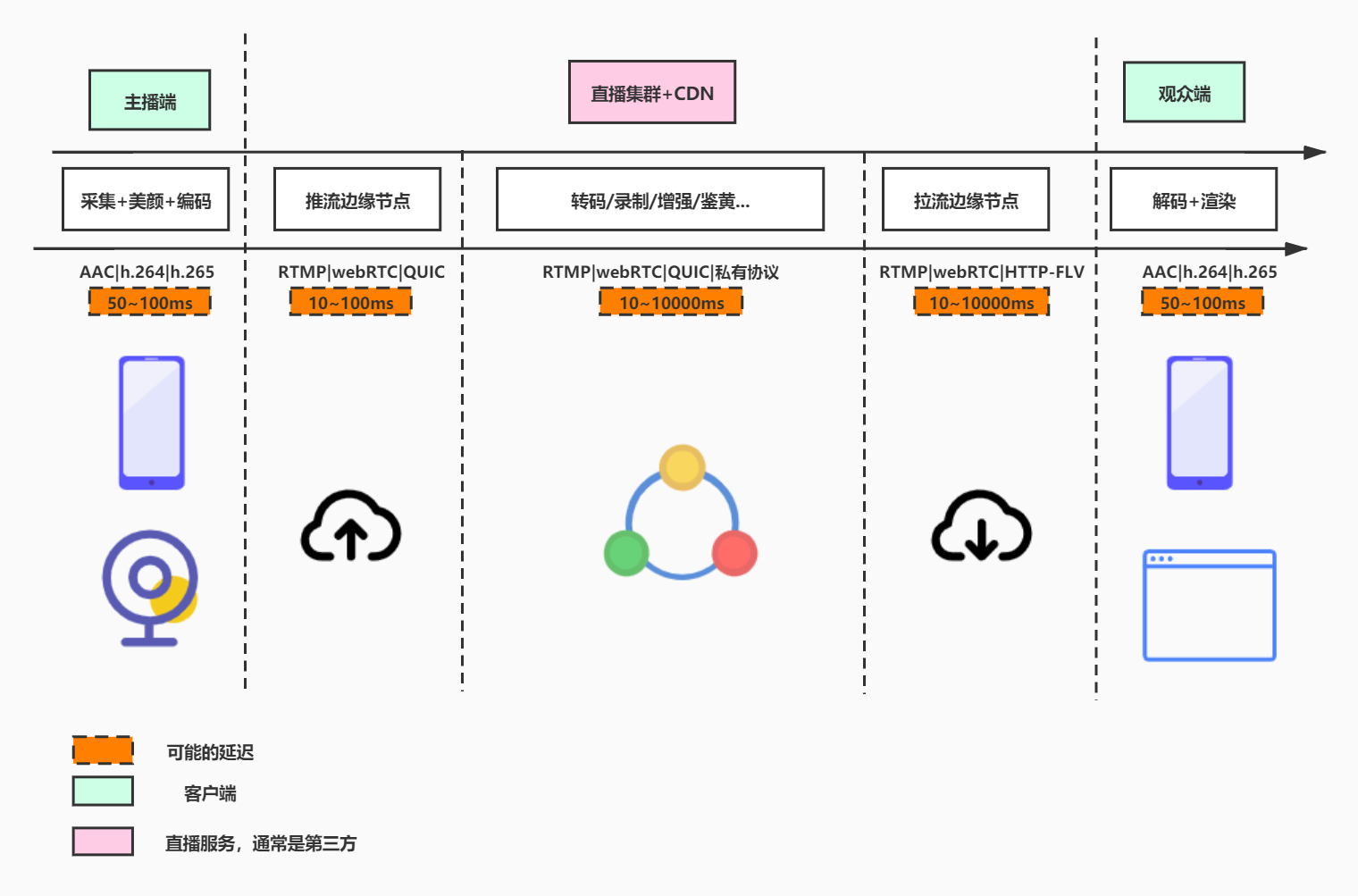
直播趋势
随着直播业务的蓬勃发展,直播技术也在不断升级演进,目前下列几点也是行业在探索的方向
- 流媒体传输协议的演变以及WebRTC和QUIC在直播的运用
- 流媒体编解码的优化以及与AI的结合
- 更高清的清晰度
- 更智能的CDN